
今更聞けない!CPU, Memory 使用率の見方
気持ちを抑えられずありがちなタイトルを付けました。
サーバ負荷監視時のボトルネックの特定をする為、
実際に手を動かして自分で見て解決するというチュートリアルとして
本記事を参照いただければ何よりです。
サーバに接続し辛い

- ブラウザから URL を打ち込みサイトにアクセスするもページが表示されない
- API が timeout する
上記の様な事象が発生した場合は
監視グラフに異変が起きているはずです。
その監視グラフを元に
アクセスしづらくなった徴候のある負荷状況を確認し
ボトルネックを特定していきます。
以下、出来るだけ原理を知る上で CLI を元に話を進めていきます。
サーバに CPU 負荷を掛ける

CPU 負荷を掛けるツールとしてLinux の I/O や CPU の負荷とロードアベレージの関係を詳しく見てみるのスクリプトを拝借しました。
※ありがとうございます @kunihirotanaka 社長!
- loadtest.pl
- arg1: 並列実行するプロセス数
- arg2: システムコールするプログラムを動作させるか判定
1 | #!/usr/bin/perl |
ロードアベレージを 2 に近づける様に CPU 負荷を掛ける
1 | $ chmod +x ./loadtest.pl |
CPU 使用状況確認コマンド
- リアルタイム監視 →
top,vmstat - 過去確認 →
sar
リアルタイム監視
top で概要確認
1 | $ top |
1 | top - 12:12:39 up 592 days, 18:55, 4 users, load average: 1.97, 1.13, 0.46 |
上記結果から
- Load Average が上昇している
%CPU,COMMANDから上昇の原因はloadtest.pl
暫定的な対処としてはこのプロセスを kill することで負荷を止めることができます。
1 | $ kill -9 6528 |
処理途中でプロセスを kill してしまい不整合が発生する様な処理の場合は
別途、CPU の増強等を検討する等、状況によりますが対応を検討する必要があります。
CPU 使用率高いランキング Top10 表示
1 | $ ps ax --sort=-%cpu -o command,pid,pid,%cpu|head -n 11 |
※ -n 11 なのは 1 行目はカラム名が入る為
1 | COMMAND PID PID %CPU |
グラフで見る
これまで CLI で確認した考察の答え合わせとして確認しましょう。
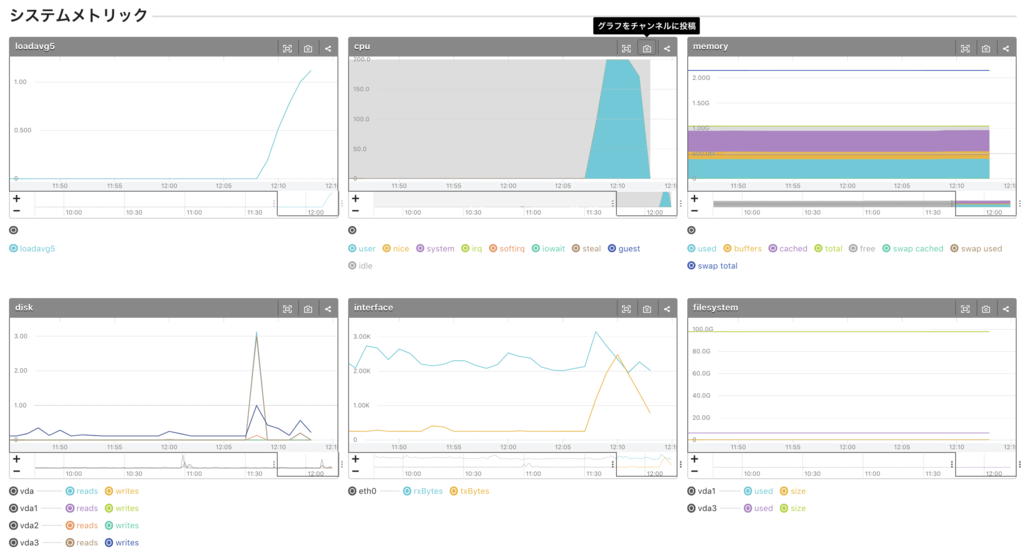
- 12:07 辺りから負荷上昇
- loadavg5 急上昇
- CPU user 急上昇。 CPU system はそこまで上がっていない。
→ アプリケーションのプロセスが CPU を食っている。 - memory は消費していない
top コマンドの様にどのプロセスが原因かまではグラフからは不明です。
サーバにアクセスして 12:07 あたりからのログを調査する等原因を特定していきます。
補足
ちなみに
Apache のモジュールとして PHP を利用している場合は COMMAND に httpd と表示されます。fluentd は ruby で実行されているので ruby です。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
12376 apache 20 0 833m 115m 19m S 2.4 3.1 0:03.52 httpd
1455 td-agent 20 0 461m 74m 0 S 1.2 2.0 1098:30 ruby
vmstat で CPU 使用率確認
1 秒ごとに出力
1 | $ vmstat 1 |
上記から以下のことが確認できます。
./loadtest.pl 2を実行中はprocs r (実行中プロセス) = 2となっているcpu usが 100%,cpu idが 0%cpu idがなくなり、プログラムが 100% CPU を食いつぶしている
system in(割り込み回数)、system cs(コンテキストスイッチ回数) が増加- コンテキストスイッチ自体が CPU を食いシステムの負荷を上げている
過去確認
1 | $ sar -u -s 21:00:00 -e 22:10:00 -f /var/log/sa/sa31 |
sar コマンドは過去まで遡って確認できるので便利です。
sar -q 実行結果各項目
| Item | Explain |
|---|---|
| runq-sz | CPU を実行する為のメモリー内で待機中のカーネルスレッド数。 通常、この値は 2 未満になる。 値が常に 2 より大きい場合は、システムが CPU の限界に到達している可能性がある |
| plist-sz | プロセスリストのプロセスとスレッド数 |
| ldavg-1 | 過去 1 分間のロードアベレージ |
| ldavg-5 | 過去 5 分間のロードアベレージ |
| ldavg-15 | 過去 15 分間のロードアベレージ |
システムコールを伴う CPU 負荷
ロードアベレージを 2 に近づける & システムコールする様に CPU 負荷を掛ける
1 | $ ./loadtest.pl 2 1 |
vmstat で監視
1 | $ vmstat 1 |
- loadtest.pl からシステムコールが多数実行される為、
cpu sy上昇している。
グラフで見る
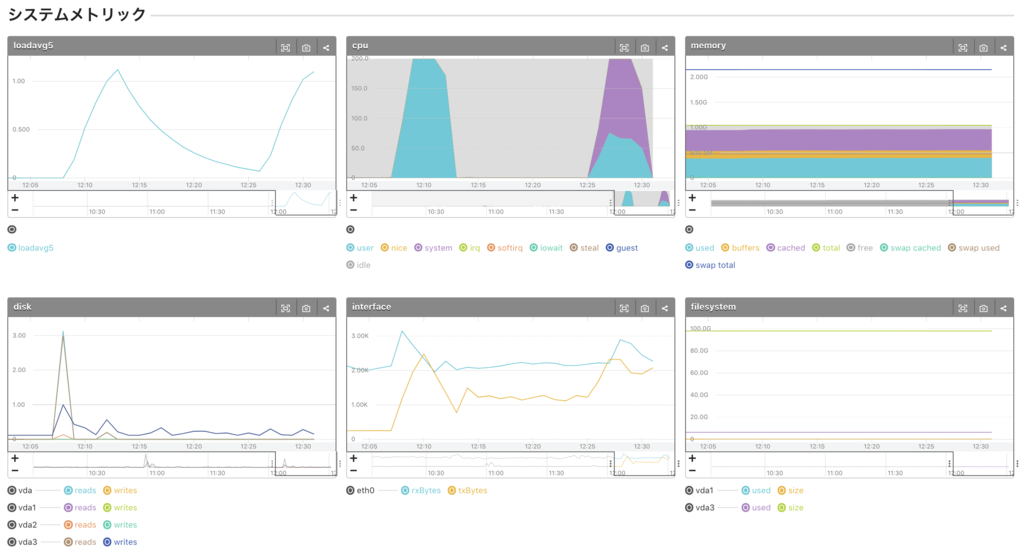
- 12:25 辺りから負荷急上昇
- loadavg5 急上昇
- CPU user, system 共に急上昇。 system の割合が多い
→ システムコールを伴うアプリケーションのプロセスが CPU を食っている。 - memory は消費していない
対応例
- アプリケーションの CPU 使用箇所の特定
- datadog, NewRelic 等の APM(Aplication Performance Management) 導入しアプリケーションのボトルネック抽出し修正
- コストこそ掛かりますが非常に有用です
- datadog, NewRelic 等の APM(Aplication Performance Management) 導入しアプリケーションのボトルネック抽出し修正
- CPU 増設
- 対象アプリのプロセスを kill (先ほどの プロセス kill )
- 例)管理画面で集計処理し、DB に負荷掛けサービスに影響してしまった時に集計処理のプロセスを kill
サーバにメモリ負荷を掛ける

- memorytest.pl
1 秒毎に 20MB 消費する様に設定
1 | #!/usr/bin/perl |
- メモリ負荷実行
1 | $ chmod +x ./memorytest.pl |
メモリ使用状況確認コマンド
- リアルタイム →
top -a,free - 過去確認 →
sar
残メモリ確認
top で概要確認
1 | $ top -a |
もしくは top 実行後、 Shift + m
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6780 mameko_d 20 0 385m 362m 1212 S 5.3 36.4 0:01.88 memorytest.pl
上記結果から
%MEM,COMMANDから上昇の原因はmemorytest.pl
暫定的な対処としては loadtest.pl と同様、プロセスを kill することで負荷を止めることができます。
1 | $ kill -9 6780 |
free で残メモリ確認
1 | $ free |
何度か実行すると徐々に Mem の
used上昇free減少- free 減少に引っ張られて
buffers,cached減少
free 実行結果各項目
- Mem: 実メモリ
- Swap: 仮想メモリ
| Item | Explain |
|---|---|
| shared | プロセス間で共有できる領域用メモリ |
| buffers | buffer に利用されるメモリ I/O アクセスする時に、直接 I/O に行くのではなく、キャッシュ経由でアクセスさせる為のメモリ |
| cached | ページキャッシュ用メモリ アプリで実メモリが必要な際は、 cached のメモリが破棄される |
確認観点
上記 free コマンド実行結果から解放されたメモリは
1 | Mem free 111388 kB = 108 MB |
これだけでは 108 MB が残りと思いがちですが
通常、各プロセスにメモリ割り振った残りを buffer と cache に利用して disk I/O を軽減している為、
buffer + cache も含まれます。
実質、残メモリはどこ見れば良い?
free + buffers + cached
= 111388 + 29764 + 204492 kB
= 345644 kB
= 338 MB
= -/+ buffers/cache free
以上から
残メモリの目安は -/+ buffers/cache free 確認 or スラッシングを確認します。
Swap 発生は何を見ればわかる?
vmstat 実行してスラッシングが発生しているか確認
スラッシング確認方法
- si (swap in from disk), so (swap out to disk) が多発している場合、スラッシングが発生しています
- so が比較的高い場合、メモリ不足の可能性大
1 | $ vmstat 1 |
- bo (block out to device) … ブロックデバイスに送られたブロック
- bi (block in from device) … ブロックデバイスから受け取ったブロック
物理メモリ使用量(Resident Set Size)高いランキング Top10 表示
1 | $ ps ax --sort=-rss -o command,pid,ppid,vsz,rss|head -n 11 |
グラフで見る
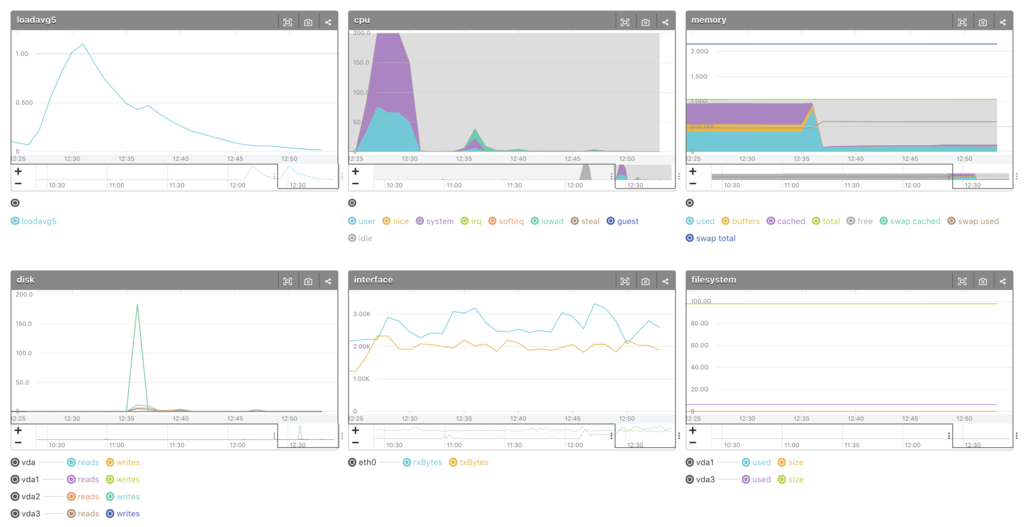
- 12:35 辺りからメモリ急上昇
- cached 減、 used 増
対応例
- プロセスレベルで監視
- datadog, mackerel, prometheus, zabbix 等監視ツール導入
- メモリ増設
- 対象アプリのプロセスを kill (先ほどの プロセス kill )
Disk I/O
I/O ディスク利用状況 確認
1 | $ sar -b -s 13:00:00 -e 14:00:00 -f /var/log/sa/sa31 |
sar -b 実行結果項目
| Item | Explain |
|---|---|
| tps | 1秒あたりの転送 (デバイスに対する IO リクエスト) 数の合計 |
| rtps | 1秒あたりの読み込み IO リクエストの回数の合計 |
| wtps | 1秒あたりの書き込み IO リクエストの回数の合計 |
| bread/s | 1秒あたりの(ブロック単位)読み込み IO リクエストのデータ量の合計 |
| bwrtn/s | 1秒あたりの(ブロック単位)書き込み IO リクエストのデータ量の合計 |
確認観点
- I/O 待ち増加する原理
1 | プロセスのメモリ消費量増 |
対策
- メモリの使用状況と Swap 確認
まとめ
CPU, Memory 使用率が上昇する原理を知った上で監視をすると
全然グラフの見え方が違うことを実感しました。
本来はグラフから見ることになるかと思います。
その際に top, vmstat, sar を実行した時の数値の変化の仕方をイメージすると
より原因追及に大きな一歩となると思います。
以上
少しでも参考になれば幸いです。
Reference
- vmstat コマンドの読み方
- 単独のサーバーの「負荷」の正体を突き止める
- 「非エンジニア」でもできるサーバ過負荷対策。ロードアベレージ、CPU 使用率、I/O ディスク利用状況、メモリ使用量の調査方法
- サーバ負荷の原因を探る方法
- Linux Performance Measurements using vmstat
- Linux の I/O や CPU の負荷とロードアベレージの関係を詳しく見てみる
補足
Swap とは?
カーネルがほぼ利用されていないメモリを検出して排除している状態を表示しています。
- メモリの空きを入出力のバッファとキャッシュに使用
- さらに活動が少ない部分をメモリから排除して swap へ押し出す
- swap からバッファやキャッシュに転用
その為、 swap が発生している、といって慌てない。
Swap を利用する意義
メモリ不足でもメモリの一部をディスクに退避させて計算し続けることができます。
メモリを使い切った様に見せつつもまだ使える仕組みを 仮想メモリ と言います。
スラッシングとは?
実メモリ と Swap のメモリの移動が大量発生し処理が遅延する現象です。
sar コマンドがない場合はインストール
1 | // CentOS |